01 理想VLA最近更新了點啥
就在 12 月初,理想發了一款 AI 眼鏡 Livis,VLA 也推送了8.1 版本的 OTA 更新。
都有點啥新東西呢?現在我們可以用 AI 眼鏡來遠程控制汽車空調后備廂,方便了不少。
坐在車上的時候,也可以直接告訴理想同學我想讓它往哪走、速度快點還是慢點。
未來,理想同學還能分析并且記住我們的喜好,記住剛剛走過的路。
以后出行的時候就能根據我的偏好設計路線和駕駛風格。
甚至能幫我們買瘋狂星期四,不用下車就能拿的那種。

理想同學幫你點瘋狂星期四
理想的 VLA 是啥呢?
VLA,也就是視覺(Vision)-語言(Language)-行動(Action)三合一的大模型。
相當于是把理想過去的端到端 + VLM 技術進一步集成起來。
現在的車載大模型既能充分理解,又能高效執行。
用上新版本的 VLA 之后,理想的輔助駕駛有啥變化呢?

一方面,VLA 模型空間感知能力更廣,還能基于擴散模型來實現軌跡生成,推理能保證 10 Hz 以上的幀率,效率非常高。
VLA 還有個能力就是跟你對話,在 OTA 8.1 版本推送之后,VLA 指令的響應速度能達到 200 毫秒,這也就意味著可以更快、更精準地響應你的行車指令。
要是我們問一些比較復雜的問題,理想同學的深度思考時間能進一步壓縮,可以說越來越接近真人對話的效果了。
有些車主也提到,在面對施工改道、加塞之類場景的時候,VLA 控制下處理更加絲滑,不會猛然加減速,那種機械感很強的點剎和變道不及時的問題也減少了。

提前預判匯入主路
軌跡生成這塊,擴散模型的好處就在于,可以直接生成一條很平滑,很“老司機”的路線來執行,軌跡輸出不再猶豫。
這也就讓車的行駛軌跡更果斷、更絲滑,也就是更像個老司機的感覺。
這樣,輔助駕駛更像真人司機操控的感覺,不安心的感覺進一步減弱了,舒適度自然也提升了不少。
理想自動駕駛的負責人郎咸朋也說到,理想 VLA 就是在用 GPT 的方式做自動駕駛。長此以往,VLA 會越來越多的生成接近真人的行為。
02 VLA的方向是具身智能
理想為啥要做 VLA?為啥要讓輔助駕駛更像人?其實得從李想對公司定位的思考說起。

他認為,現在我們所說的具身智能其實有兩個大的品類,一種是人形的具身智能機器人,另一種是常見工具智能化之后的具身智能機器人。
這就有點像擎天柱或者大黃蜂的汽車形態,雖然工具屬性更強,但同樣具備擬人的思考能力,行為方式。

從這個角度來看,汽車機器人它也可以是具身智能機器人。
理想第三季度財報業績會上,李想深入分析了未來十年新產品要走的路線:
產品停留在“電動車”階段時,車企們的競爭就會演變成參數大戰。更高的結構強度、更大的車內空間、更久的電池續航、更低的首發價格……永不休止的內卷之下,所有額外的研發投入都會變成成本浪費。
當產品演變成“智能終端”,車企們的目光又會全部聚集到屏幕上,像手機研發那樣重復進行類似的系統建設。
所有的工作都是如何把手機 App 搬進車機里,卷到最后,就會變成用車機寫代碼,用車機做深度研究。
這些投入,就徹底偏離了用戶需求。
因此,理想未來路線就十分明確了:
不只是要做電動汽車,不只是要做有輪子的智能手機,而是要做具身智能,要做大黃蜂這樣的汽車機器人。
放眼更廣的領域,L4 級自動駕駛的車,是跑在路上的汽車機器人,升級后的智能座艙,是會思考的空間智能體,AI 眼鏡,是戴在頭上的穿戴機器人,甚至如今的座椅,都可以進一步改造,感受你的體溫、體重,不需要任何多余的空間,就能變成一個默默關心你的健康機器人……
那就要賦予汽車眼睛和耳朵一樣的感知能力,大腦和神經一樣的模型能力。
讓汽車具備私人司機一樣的專業能力和服務,既可以開車上路、開門接你,又可以幫你停車、充電。在車里給你提供飛機頭等艙級別的服務,像助理一樣幫你處理手上的事務。
畢竟,誰不想要一臺平時提供便捷和關懷,有事的時候真出力的大黃蜂呢?
03 上一代的上限 是下一代的起點
從這個思路回頭去看,理想 VLA 在做的事就不難理解了。
之前的端到端 + VLM 是有短板的。
一方面,輔助駕駛缺少思考能力,只能簡單模仿人類駕駛行為,而人類駕駛場景是無窮無盡的,無法通過模仿學習全部學會。
另一方面,VLM 雖然擁有視覺能力,但是也僅能實現認識常規的紅綠燈或者標識,而不能對復雜的指示牌進行思考。
這就有點像車里有個教練在副駕駛教學員操作,我們坐在車上,體驗多少有點僵硬了。
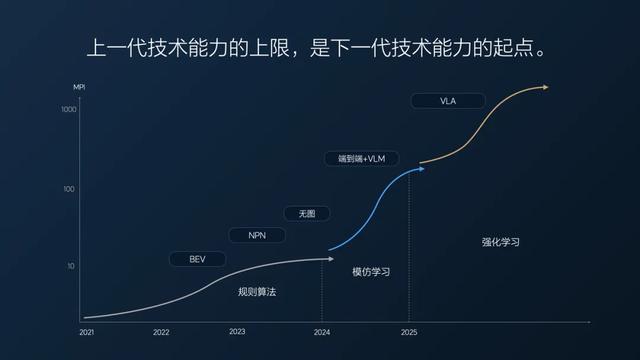
上一代技術的上限,是下一代技術的起點。
想要解決就得將二者進一步整合起來,這才有了 VLA 模型。
理想 VLA 的進化,不是給工具戴上“外置大腦”,而是讓工具的本體具身智能化。
從最顯眼的數據上來看,我們人類開車上路,剎車、轉向的最快響應速度差不多 450 毫秒。
原先的輔助駕駛差不多 550 毫秒,在司機眼里就是反應慢。
而線控體系可以讓整個鏈路響應速度縮減到 350 毫秒,低于人類一般水平,在一些場景下甚至能讓司機感受到“比人開得好”。
從感知上,目前大量采用的 3D BEV、OCC 占用網絡、2D ViT,有效的感知距離不如人眼。3D ViT 的工作原理和人眼類似,有效距離可以比以往擴大兩到三倍。
我們可以期待一下,將來用上 3D ViT 之后,理想 VLA 大模型可以用更接近人類視覺的方式觀察環境,能更好地理解物理世界,也能更高效地使用人類數據做訓練。
應用場景也可以不再局限于輔助駕駛,能在車內外給用戶提供交互。或許還會誕生更多不同形態的機器人和應用。

如今的理想 VLA 完成了軟硬件的全面整合,這也意味著很難有第三方能加入這一賽道,供應同級別的整個 AI 系統。
理想要在 AI 技術上持續保持優勢,就必定會堅持走全面自研這條路子,維持研發投入。
對此,理想的決定是,公司架構重新轉型成創業公司,進一步聚焦具身智能這個新賽道,重新出發。
在自研芯片與自主泊車、遠程呼叫之類各種創新功能落地之后,我們一定會看到一個擁有深度智能的、自主服務用戶的,更加“理想”的智能出行生態。
未來十年,我們說不定也會看到許許多多“汽車人”,它們不但是頂級司機,更是家庭管家、生活助理。以汽車的形態,提供更多便捷與陪伴。



