
作者|周一笑
郵箱|zhouyixiao@pingwest.com
四個月前,GPT-5 發布時一堆人吐槽,跑分是高了,但聊天冷冰冰;一個月前,GPT-5.1 回應了這波差評,主打“更好聊、更好調”,算是把人味兒找回來了。
結果還沒暖熱乎,Google 的 Gemini 3 就殺了過來,直接把 LMArena 榜單屠了個遍。緊接著 Anthropic 的 Claude Opus 4.5 也上線,在編程榜單上把 OpenAI 按在地上摩擦。
于是就有了昨天凌晨的 GPT-5.2。
這次發布的背景很微妙,就在幾天前,有媒體爆出 Sam Altman 在內部發了一封Code Red郵件,要求全公司集中資源改進 ChatGPT。雖然官方說 GPT?5.2 不是專門為 Gemini 3 趕出來的,但 Code Red 和發布時間點都說明:Gemini 3 至少加快了 OpenAI 把這版推向用戶的步伐。
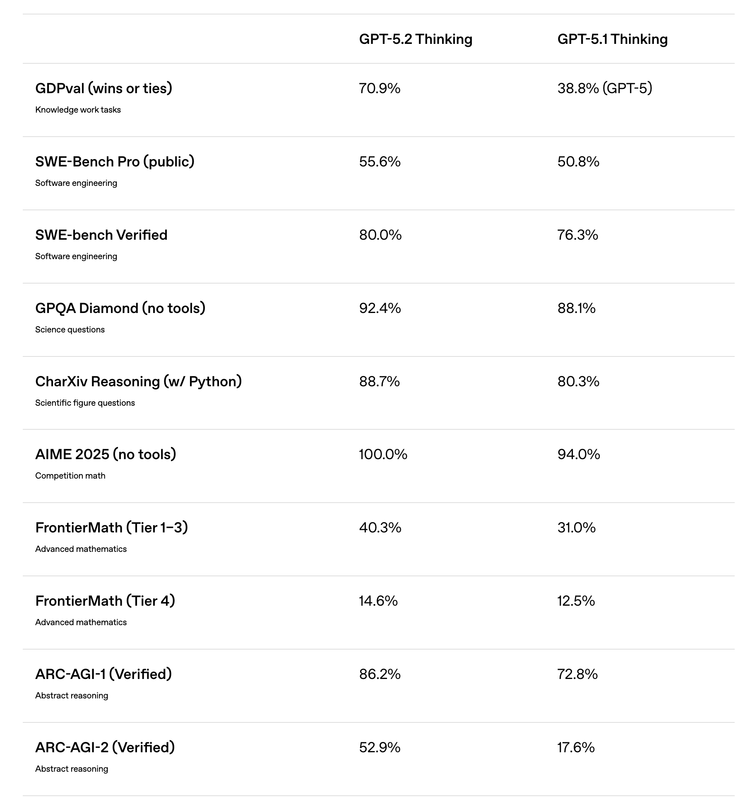
這一次,OpenAI 雖然繼續強調跑分相對5.1點提升,但還在反復突出一個關鍵詞:專業知識工作。
換句話說,這次瞄準的不是“更好聊”,而是“更能干活”。
1
第一個在“真實工作”上打平人類專家的模型?
這次 OpenAI 主推的新基準測試叫 GDPval:讓 AI 去做 44 種職業的真實工作任務,比如做 PPT、做表格、寫分析報告。
成績是這樣的:
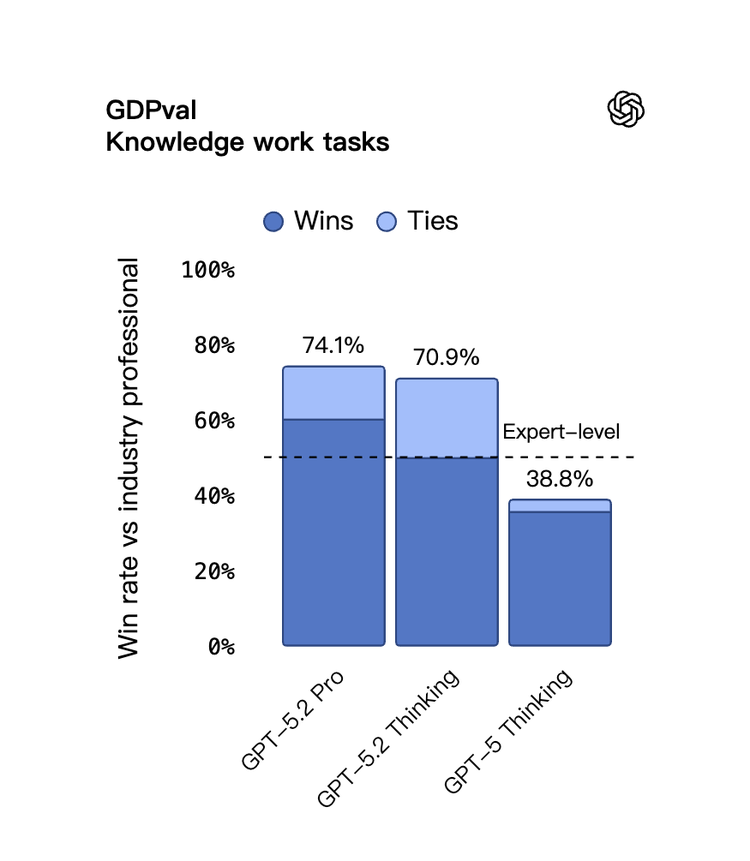
GPT-5.2 Thinking 在?70.9%?的任務上能打平或者贏過行業專家
上一代 GPT-5 才?38.8%
Claude Opus 4.5 是?59.6%
Gemini 3 Pro 是?53.5%
更夸張的是效率:速度快?11 倍,成本不到?1%。
當然,GDPval 是 OpenAI 自己搞的基準,還沒有被獨立驗證,所以這個打平人類專家的說法要打個問號。但即便打個折扣,從 38% 跳到 70%,這個提升幅度也很難忽視。
Anthropic 的 Claude 最近在這類任務上同樣進步明顯,但從 5.2 的發力方向來看,OpenAI 顯然想在"AI 替代知識工作"這條賽道上搶先卡位。
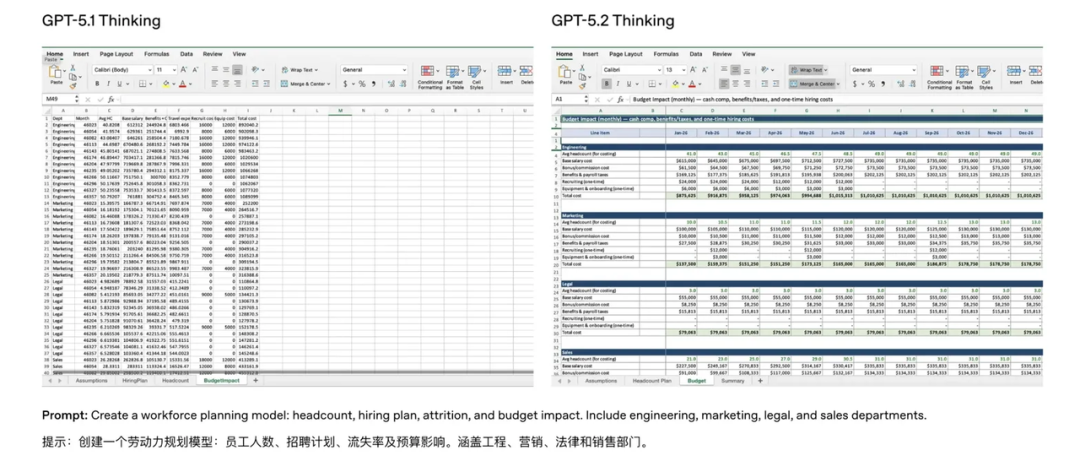
OpenAI官方也放了一些工作中的案例,比如,同樣是讓模型做一個勞動力規劃表格(包含員工人數、招聘計劃、流失率和預算影響),5.1 輸出的是一堆原始數據堆砌,5.2 則自動按部門分類、加上顏色標注和清晰的層級結構,看起來像是有人真的用心排過版。
1
Coding:前端又雙叒叕更強了
編程能力也是 5.2 的重點宣傳方向。
SWE-bench Pro:55.6%(5.1 是 50.8%,Gemini 3 Pro 是 43.3%,Claude Opus 4.5 是 52%)
SWE-bench Verified:80%(和 Claude Opus 4.5 的 80.9% 基本打平,這個榜已經快刷到極限了)
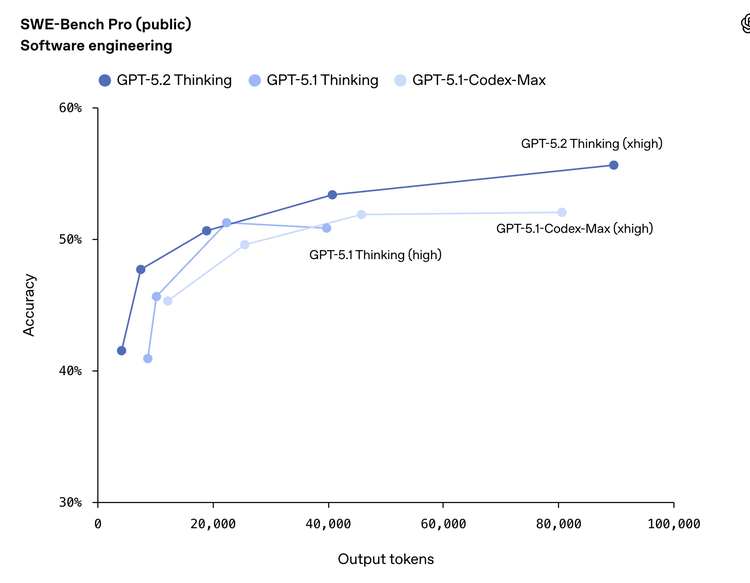
OpenAI 這次重點宣傳的是 SWE-bench Pro 而不是 Verified,角度是:Pro 版本場景更多樣、污染更少,更能反映真實的軟件工程能力。
前端開發能力又上了一個臺階,特別是在 3D 場景渲染和復雜交互界面這塊。Cognition、Warp、JetBrains、Augment Code 這些合作伙伴都表示,5.2 在交互式編程、代碼審查和 bug 查找上都有可測量的提升。
最直觀的是這個波浪模擬案例的對比,
GPT-5.2 Thinking:
Gemini 3 Pro:
1
更像數學家了
數學能力是這次升級的另一個重頭戲。
幾個關鍵數字:
FrontierMath(Tier 1-3):40.3%,創下新的行業紀錄,上一代 5.1 是 31%
AIME 2025:100%,滿分。這是第一個在不使用工具的情況下刷滿這個競賽數學基準的模型
GPQA Diamond(博士級科學問答):Thinking 版 92.4%,Pro 版 93.2%
但最讓人印象深刻的,是 GPT-5.2 Pro 在一個真正的數學研究問題上的表現。
OpenAI 在博客里提到,研究人員用 GPT-5.2 Pro 探索了一個統計學習理論中的開放問題,這個問題最早是在 2019 年的一個數學會議上提出的。在一個特定的高斯設定下,模型提出了一個證明思路,隨后被人類研究者驗證并擴展。
這不是AI 從零發現物理定律那種科幻場景,但確實是一個 AI 在人類監督下提供了非平凡的數學洞見,而且經受住了專家審查。5.1 沒有被廣泛報道做到過這一點。
用一位測試者的話說:5.1 像一個很強的數學家教和助手,5.2 開始有點"初級合作者"的意思了——尤其是配合代碼工具使用的時候。
1
API 漲價:OpenAI 的小心思
5.2 的 API 漲價了。
輸入輸出的單價都上調了約 40%:$1.75/百萬輸入,$14/百萬輸出。Pro 版本更貴,分別是 $21 和 $168。
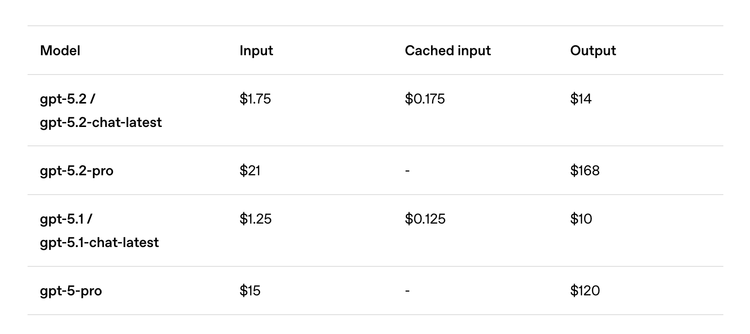
官方的解釋是:單價雖然漲了,但模型效率更高,完成同樣的任務消耗的 token 更少,所以"達到同等質量水平的總成本可能反而更低"。
但如果花更少的 token 只能達到"同等質量",那升級的意義在哪兒?要是真的又好又省,直接說"更好更便宜"不就完了?
說白了,模型確實變強了,但 OpenAI 選擇把效率提升的紅利收進自己口袋,而不是讓利給用戶。
1
幾個重點提升
除了上面這些亮點,5.2 還有幾個實打實的提升:
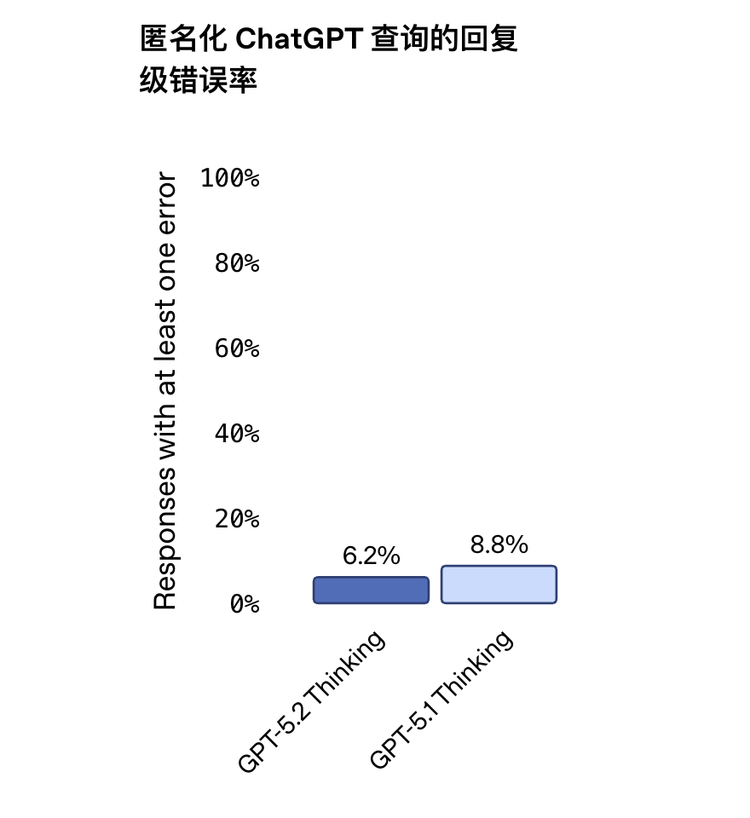
錯誤率降低 30%
這一點其實很關鍵。很多人只盯著"智商"看,但實際用下來會發現,國產模型和海外頭部模型之間,幻覺控制的差距往往比純智力差距更影響體驗。5.2 的 Thinking 版本比 5.1 的錯誤率降低了 30%,在日常決策、研究和寫作場景下會更靠譜。
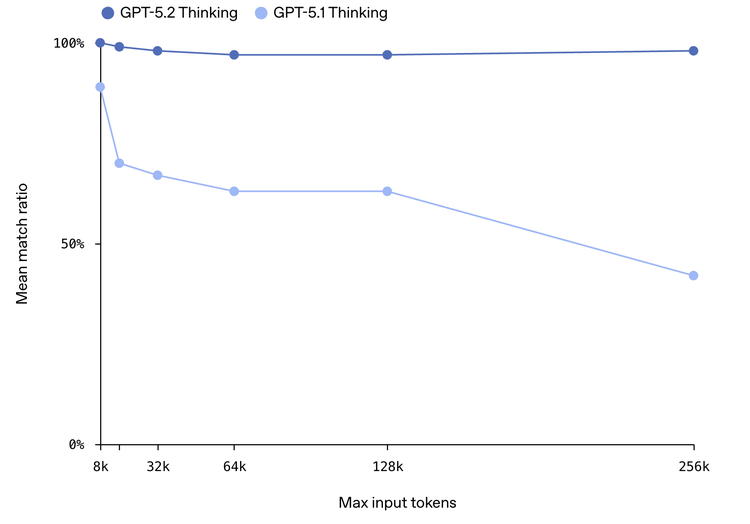
長文能力提升
以前長上下文是個老大難問題,塞太多內容進去模型就開始健忘。5.2 在 256k token 級別的測試中表現穩定,基本能把關鍵信息都記住。像合同審核、文獻梳理這種需要反復引用上文的場景,體驗會好很多。Box 反饋說,5.2 從長文檔中提取信息的速度快了 40%,推理準確率也提升了 40%。
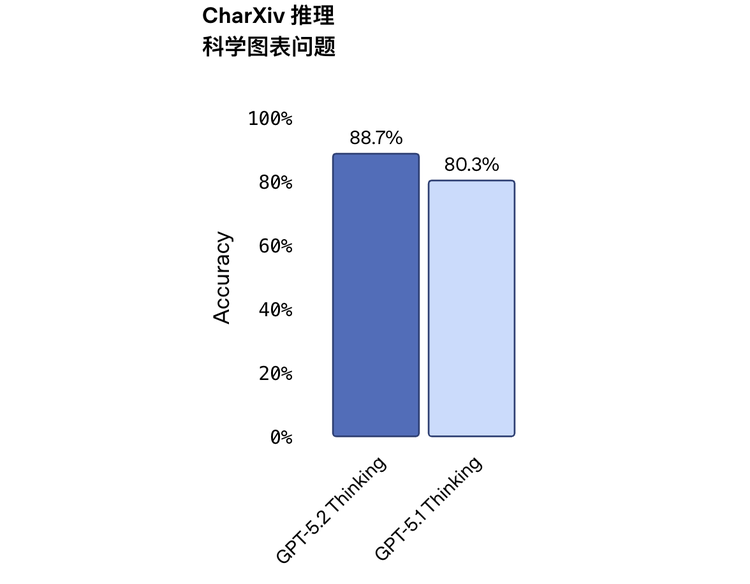
看圖能力
圖表理解、軟件界面識別這塊錯誤率砍了一半。在 CharXiv Reasoning(科學論文圖表理解基準)上,5.2 Thinking 達到了 88.7%,比 5.1 提升了 8 個百分點以上。
OpenAI 內部測試里,有人給模型一張低分辨率的主板照片,它能準確識別出關鍵元器件。這意味著以后扔給 AI 一張模糊的業務報表截圖,它大概率能直接把里面的數據結構化提取出來,這對做數據分析的人來說挺實用的,畢竟現在海外已經有不少人把 AI 當成數據分析的主力工具了。

1
Code Red 下的補課之作
拉遠一點看,GPT-5.2 本質上是一次“補課”。
從 8 月的 5.0 到 11 月的 5.1 再到 12 月的 5.2,四個月三個版本,這個節奏本身就說明問題:OpenAI 在被 Gemini 3 和 Claude Opus 4.5 逼著跑。結果就是PT?5.2 在 benchmark 上把很多榜單拉了回來,但真正有意義的是,它在長時知識工作、復雜編碼和 agent 工作流上的表現。
另外也有觀點認為,這種緊急動員 + 小步快跑的節奏可能會成為常態,年底各家都可能還有新發布。好處是各家實驗室會被倒逼著把模型做得更快、更便宜、更能變現;壞處是大家都盯著短期 benchmark 卷,真正需要長期投入的基礎性突破可能會被擠壓。
這次的社區的反饋也很多樣,做正事的用戶普遍覺得真香,長上下文、復雜推理確實更穩了;但陪聊黨和角色扮演玩家吐槽“5.2 冷冰冰的,像從好朋友變成了 HR”,人味兒又被收回去了,還有人吐槽說好的成人模式也遙遙無期。
總結一下,如果你是 ChatGPT Pro 用戶,5.2 在需要深度分析、復雜推理的場景下值得一試——做 PPT、做表格、寫報告、啃長文檔,這些方面的進步是實打實的。
但如果你期待的是日常聊天體驗的質變,可能要失望了。5.2 的真正價值,或許要等它接入 Codex 這類 agent 產品、開始真正替你跑腿干活的時候,才能完全釋放出來。
屠榜不重要,能干活才重要。這一點,OpenAI 這次算是想明白了。





點個“愛心”,再走吧


